
빅데이터가 나온 후 여기저기서 자주 듣게 되는 용어 중 하나인 맵리듀스에 대한 기본적인 내용에 대해 알아보고 간략하게 정리하고자 한다.
1. 맵리듀스란?
구글에서 대용량 데이터 처리를 분산 병렬 컴퓨팅에서 처리하기 위해 제작하여 2004년에 발표한 소프트웨어 프레임워크이다.
맵리듀스는 맵(Map)과 리듀스(Reduce)가 합져진 말로써 맵(Map)은 우리가 흔히 알고 있듯이 Key와 Value라는 두 개의 쌍으로 가지고 있는 자료구조이다. 리듀스(Reduce)는 맵(Map)의 중복된 값을 줄이거나, 값을 합쳐서 최종 결과물로 만드는 방법이라고 할 수 있다.
간단하게 말해서 맵리듀스는 맵의 데이터를 중복 제거하거나 값을 합쳐서 데이터를 만드는 것을 의미한다.
2. 맵리듀스의 처리 과정
맵리듀스의 처리과정을 다음과 같다.
1. Splitting : 입력된 데이터의 분리하는 단계
2. Mapping : 분리된 데이터를 Map 형태로 가공하는 단계
3. Shuffling : 맵핑된 데이터를 정렬, 병합 후 리듀싱 하기 위해 리듀스로 전달하는 단계
4. Reducing : 데이터를 집계하고 최종 결과물로 내보내는 단계
처리과정 중 splitting과 mapping을 합쳐서 맵 태스크, Shuffling과 Reducing을 합겨처 리듀스 태스크 라고 부른다.
이 과정을 가장 유명한 예시인 워드 카운팅으로 설명하면 다음과 같습니다.
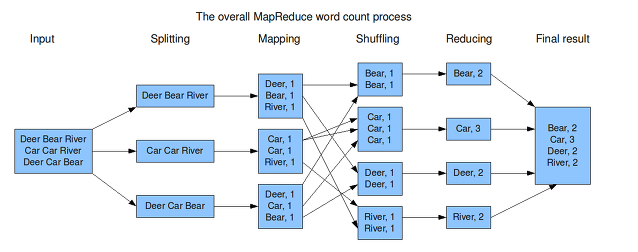
1. Input : Deer Bear River... 다양한 단어가 입력된다.
2. Splitting : 입력된 단어를 작은 단위로 나누어 각 노드에 key, value로 저장된다.
3. Mapping : Splitting에 의해 노드에 저장된 데이터를 리스트로 만들게 된다. 데이터는 list<key,value> 만들어진다.
4. Shuffling : 각 단어별로 동일한 단어를 그룹핑하여 key, list(value) 구조로 데이터를 만들게 된다.
5. Reducing : 그룹화된 각각의 단어들의 숫자를 카운트 하여 단어별 카운트 수량을 list<key, value> 구조로 생성한다.
6. Final Result : 각 단어별 카운팅 정보를 출력한다.
3. 분산, 병렬 처리가 좋은 이유?
위의 예시에서 보다시피 Input 파일이 Splitting을 통해 쪼개져 분산 파일 시스템에 저장되어있다고 가정한다. 각각 쪼개진 파일들은 2개의 큰 역할인 map을 실행할 worker, reduce를 실행할 worker로 task를 부여할 수 있다.
Mapper worker와 Reduce worker들에 대한 숫자도 별도로 지정하게 되면서 각각의 worker들은 Mapping 작업과 Reduce 작업을 동시에, 그리고 병렬로 처리하게 된다.
이러한 이유로 맵리듀스 프레임워크는 분산/병렬 처리에 강점을 보이게 된다.
'분산처리 > Hadoop' 카테고리의 다른 글
| 하둡(HDFS) 실습 (0) | 2022.07.28 |
|---|---|
| 하둡의 설치 (0) | 2022.07.28 |
| 하둡이란? - 기본 (0) | 2022.07.25 |