1. graphviz를 이용한 붓꽃 데이터의 의사결정트리 시각화
예전에 진행한 사이킷런의 붓꽃 데이터(사이킷런을 이용한 붓꽃 데이터 분류)를 가지고 graphviz로 의사결정트리를 시각화 해보고 결정 트리의 주요 하이퍼 파라미터를 알아보자
⎷ 실습
먼저 붓꽃 데이터를 불러오고 graphviz를 통해 시각화한 결과를 살펴보자.
이때 결정 트리의 하이퍼 파라미터는 default 값으로 셋팅한 결과이다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import export_graphviz
import graphviz
# DecisionTree Classifier 생성
dt_clf = DecisionTreeClassifier(random_state=156)
# 붓꽃 데이터를 로딩하고, 학습과 테스트 데이터 셋으로 분리
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target,
test_size=0.2, random_state=11)
# DecisionTreeClassifer 학습.
dt_clf.fit(X_train, y_train)
# export_graphviz()의 호출 결과로 out_file로 지정된 tree.dot 파일을 생성함.
export_graphviz(dt_clf, out_file="tree.dot", class_names=iris_data.target_names, \
feature_names= iris_data.feature_names, impurity=True, filled=True)
# 위에서 생성된 tree.dot 파일을 Graphviz 읽어서 Jupyter Notebook상에서 시각화
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)▶ Out
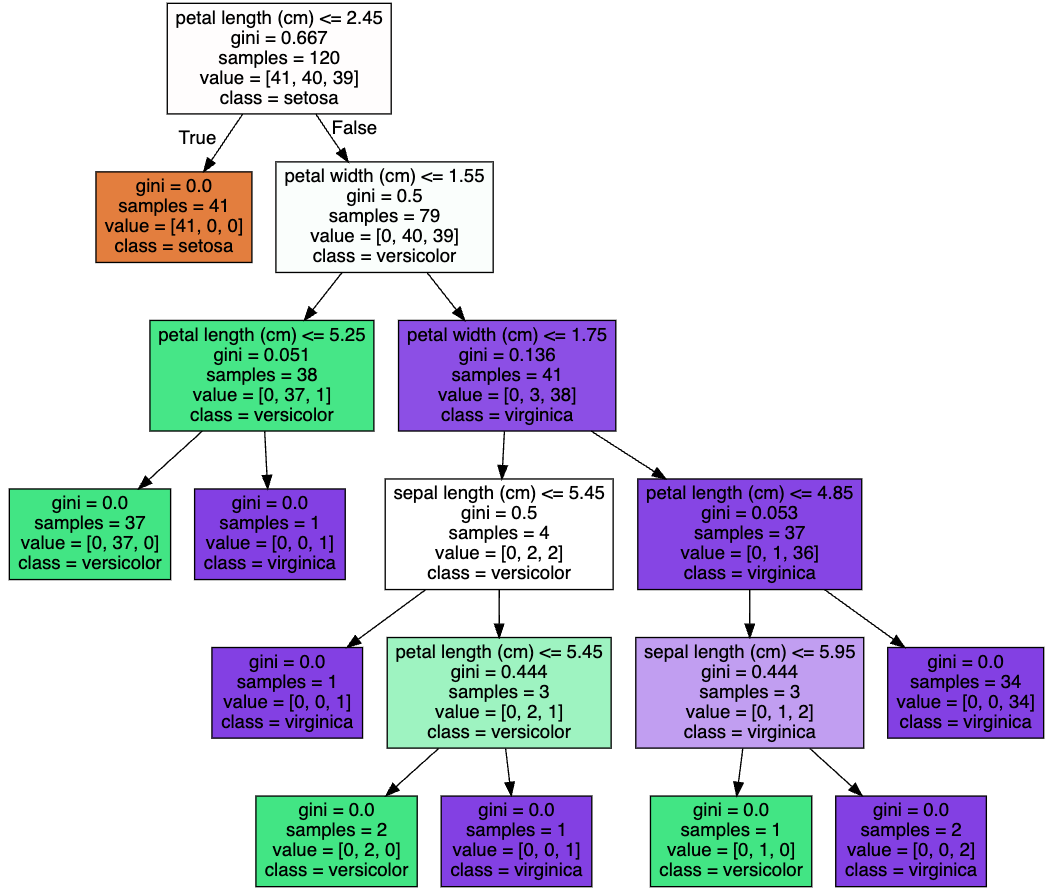
2. 하이퍼 파라미터 - max_depth
max_depth는 트리의 최대 깊이를 말한다.
default는 None으로 None으로 설정하면 완벽하게 클래스 결정 값이 될 때까지 깊이를 계속 키우며 분할하거나 노드가 가지는 데이터 개수가 min_samples_split보다 작아질 때까지 계속 싶이를 증가시킨다.
깊이가 깊어질 경우 min_samples_split 설정대로 최대 분할하여 과적합할 수 있으므로 적절한 값으로 제어가 필요하다.
⎷ 실습
위의 DecisionTree Classifier에 파라미터에 max_depth를 3으로 셋팅하고 결과를 살펴보면 기존 5개의 depth에서 3개의 depth로 변경됨을 확인할 수 있다.
# DecisionTree Classifier 생성 및 max_depth를 3으로 셋팅
dt_clf = DecisionTreeClassifier(random_state=156, max_depth=3)▶ Out
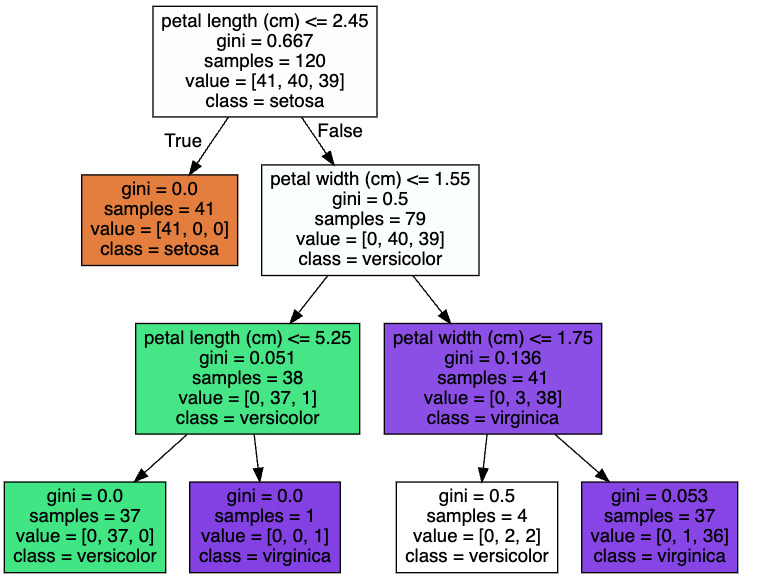
3. 하이퍼 파라미터 - max_features
최적의 분할을 위해 고려할 최대 피처 개수이다.
- 디폴트는 None으로 데이터 세트의 모든 피처를 사용해 분할을 수행한다.
- int형으로 지정하면 대상 피처의 개수, float형으로 지정하면 전체 피처 중 대상 피처의 퍼센트로 선정한다.
- 'sqrt'는 전체 피처 중 sqrt(전체 피처개수), 즉 √전체피처개수 만큼 선정한다.
- 'auto'로 지정하면 sqrt와 동일하다.
- 'log'는 전체 피처 중 log2(전체 피처 개수)로 선정한다.
⎷ 실습
max_features를 낮추게 되면 각 노드에서 사용할 수 있는 특성의 수가 제한된다. 그리고 이로 인해 트리의 깊이가 증가하게 되고 복잡성 또한 증가하게 된다. max_features를 3으로 셋팅하고 결과를 살펴보면 복잡성이 증가한 것을 확인할 수 있다.
# DecisionTree Classifier 생성 및 max_features3으로 셋팅
dt_clf = DecisionTreeClassifier(random_state=156, max_features=3)▶ Out
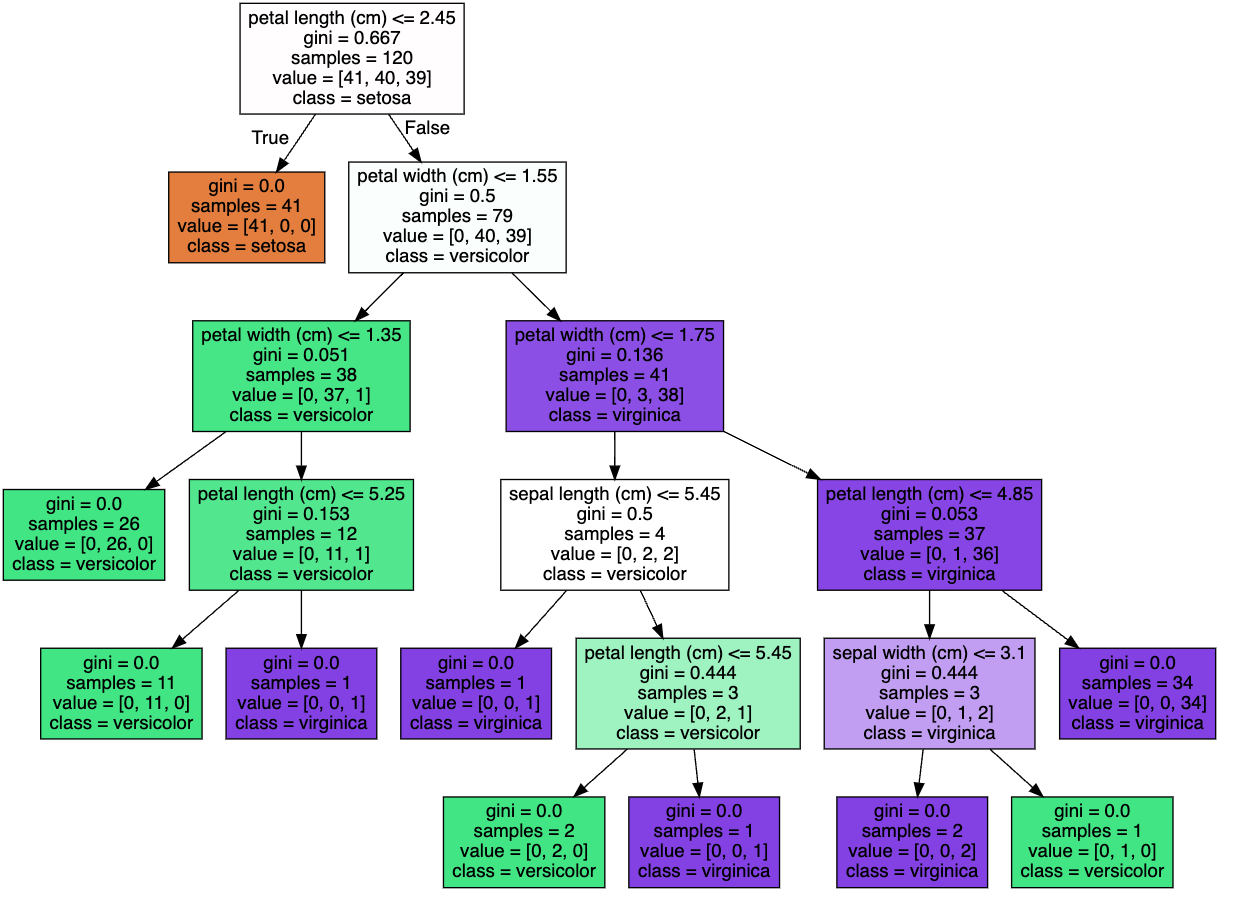
4. 하이퍼 파라미터 - min_samples_split
노드를 분할하기 위한 최소한의 샘플 데이터 수로 과적합을 제어하는데 사용된다.
디폴트는 2이고 작은 값이 설정될수록 분할되는 노드가 많아져서 과적합 가능성이 높아진다.
⎷ 실습
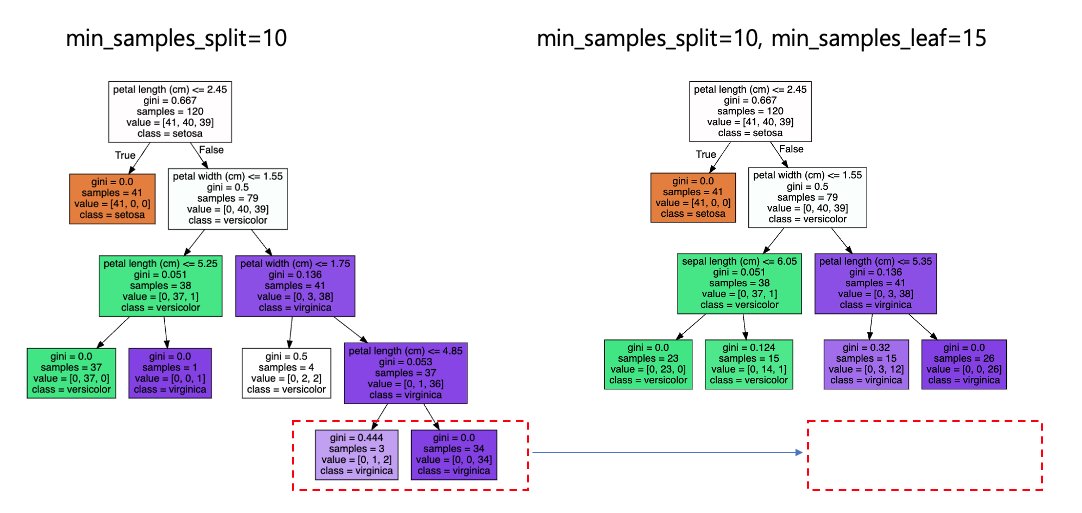
min_samples_split 값을 default 2에서 10으로 높이게 되면 리프노드가 되기 위한 최소 샘플수가 커지게 되므로 트리의 깊이는 default 값에 비해 얕아진다.
# DecisionTree Classifier 생성 및 min_samples_split 10 셋팅
dt_clf = DecisionTreeClassifier(random_state=156, min_samples_split=10)▶ Out
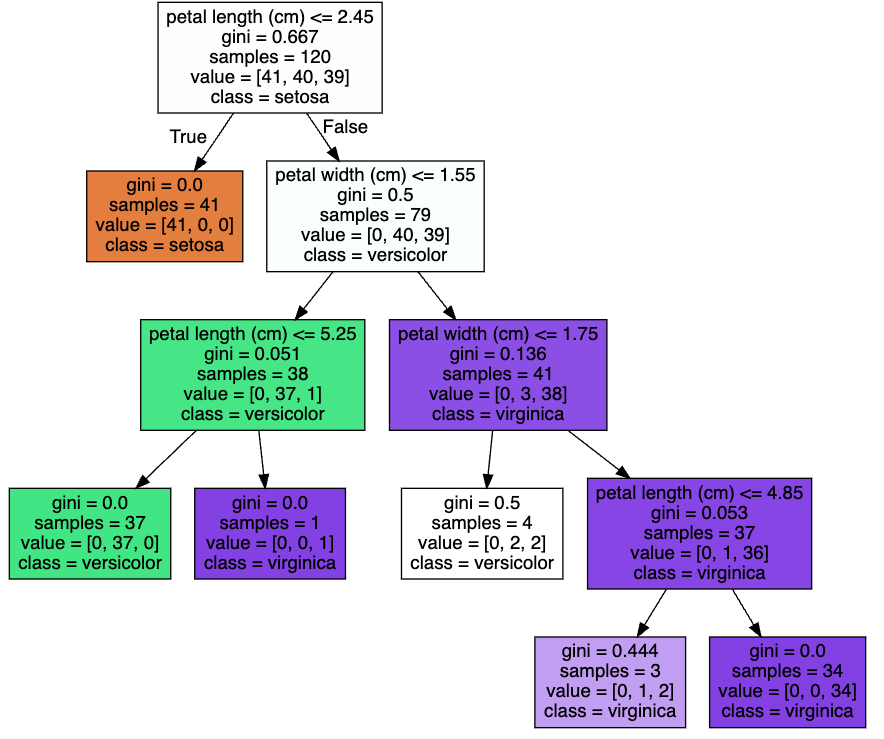
5. 하이퍼 파라미터 - min_samples_leaf
말단 노드(Leaf)가 되기 위한 최소한의 샘플 데이터 수를 설정하기 위한 값이다.
min_samples_split와 유사하게 과적합 제어 용도이다. 그러나 비대칭적 데이터의 경우 특정 클래스의 데이터가 극도로 적을 수 있으므로 이러한 경우에는 작게 설정해야한다.
min_samples_split 기준에 맞아서 분할을 하더라도 min_samples_leaf 기준에 맞지 않아서 leaf 노드를 만들 수 없으면 최종 leaf 노드로 생성할 수 없다.
만약, min_samples_split = 6, min_samples_leaf가 4인 경우를 살펴보자. 6개의 sample로 node에 개별 클랙스 값이 각각 3개씩 들어가 있으면 min_samples_leaf의 최소 개수가 4이기 때문에 leaf node로 만들 수 없어서 분할 할 수 없다.
⎷ 실습
위의 min_samples_split은 10으로 유지하고 min_samples_leaf를 15로 변경한 경우 기존에 samples =3인 leaf 노드는 생성 되지 못한 것을 확인할 수 있다.
# DecisionTree Classifier 생성
dt_clf = DecisionTreeClassifier(random_state=156, min_samples_split=10, min_samples_leaf=15)▶ Out
6. 하이퍼 파라미터 - max_leaf_nodes
말단 노드(leaf)의 최대 개수이다.
⎷ 실습
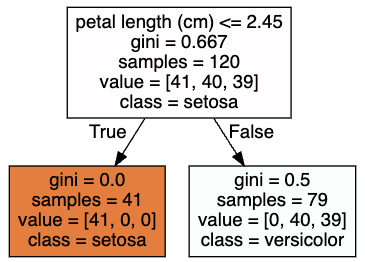
위의 max_leaf_nodes 2로 지정하면 2개의 노드로만 구성된다.
# DecisionTree Classifier 생성
dt_clf = DecisionTreeClassifier(random_state=156, max_leaf_nodes=2)▶ Out
'ML > 분류(Classification)' 카테고리의 다른 글
| 사용자 행동 인식(Human Activity Recognition) 데이터 세트를 활용한 결정트리 실습 (0) | 2024.05.22 |
|---|---|
| 결정트리의 과적합(Overfitting) (0) | 2024.05.07 |
| 특성 중요도(feature_importances_) (0) | 2024.04.22 |
| 결정 트리란? 엔트로피, 정보이득, 그리고 지니계수 (0) | 2024.04.02 |
| 분류(Classification)와 대표적인 알고리즘 (0) | 2024.04.02 |
1. graphviz를 이용한 붓꽃 데이터의 의사결정트리 시각화
예전에 진행한 사이킷런의 붓꽃 데이터(사이킷런을 이용한 붓꽃 데이터 분류)를 가지고 graphviz로 의사결정트리를 시각화 해보고 결정 트리의 주요 하이퍼 파라미터를 알아보자
⎷ 실습
먼저 붓꽃 데이터를 불러오고 graphviz를 통해 시각화한 결과를 살펴보자.
이때 결정 트리의 하이퍼 파라미터는 default 값으로 셋팅한 결과이다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import export_graphviz
import graphviz
# DecisionTree Classifier 생성
dt_clf = DecisionTreeClassifier(random_state=156)
# 붓꽃 데이터를 로딩하고, 학습과 테스트 데이터 셋으로 분리
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target,
test_size=0.2, random_state=11)
# DecisionTreeClassifer 학습.
dt_clf.fit(X_train, y_train)
# export_graphviz()의 호출 결과로 out_file로 지정된 tree.dot 파일을 생성함.
export_graphviz(dt_clf, out_file="tree.dot", class_names=iris_data.target_names, \
feature_names= iris_data.feature_names, impurity=True, filled=True)
# 위에서 생성된 tree.dot 파일을 Graphviz 읽어서 Jupyter Notebook상에서 시각화
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)▶ Out
2. 하이퍼 파라미터 - max_depth
max_depth는 트리의 최대 깊이를 말한다.
default는 None으로 None으로 설정하면 완벽하게 클래스 결정 값이 될 때까지 깊이를 계속 키우며 분할하거나 노드가 가지는 데이터 개수가 min_samples_split보다 작아질 때까지 계속 싶이를 증가시킨다.
깊이가 깊어질 경우 min_samples_split 설정대로 최대 분할하여 과적합할 수 있으므로 적절한 값으로 제어가 필요하다.
⎷ 실습
위의 DecisionTree Classifier에 파라미터에 max_depth를 3으로 셋팅하고 결과를 살펴보면 기존 5개의 depth에서 3개의 depth로 변경됨을 확인할 수 있다.
# DecisionTree Classifier 생성 및 max_depth를 3으로 셋팅
dt_clf = DecisionTreeClassifier(random_state=156, max_depth=3)▶ Out
3. 하이퍼 파라미터 - max_features
최적의 분할을 위해 고려할 최대 피처 개수이다.
- 디폴트는 None으로 데이터 세트의 모든 피처를 사용해 분할을 수행한다.
- int형으로 지정하면 대상 피처의 개수, float형으로 지정하면 전체 피처 중 대상 피처의 퍼센트로 선정한다.
- 'sqrt'는 전체 피처 중 sqrt(전체 피처개수), 즉 √전체피처개수 만큼 선정한다.
- 'auto'로 지정하면 sqrt와 동일하다.
- 'log'는 전체 피처 중 log2(전체 피처 개수)로 선정한다.
⎷ 실습
max_features를 낮추게 되면 각 노드에서 사용할 수 있는 특성의 수가 제한된다. 그리고 이로 인해 트리의 깊이가 증가하게 되고 복잡성 또한 증가하게 된다. max_features를 3으로 셋팅하고 결과를 살펴보면 복잡성이 증가한 것을 확인할 수 있다.
# DecisionTree Classifier 생성 및 max_features3으로 셋팅
dt_clf = DecisionTreeClassifier(random_state=156, max_features=3)▶ Out
4. 하이퍼 파라미터 - min_samples_split
노드를 분할하기 위한 최소한의 샘플 데이터 수로 과적합을 제어하는데 사용된다.
디폴트는 2이고 작은 값이 설정될수록 분할되는 노드가 많아져서 과적합 가능성이 높아진다.
⎷ 실습
min_samples_split 값을 default 2에서 10으로 높이게 되면 리프노드가 되기 위한 최소 샘플수가 커지게 되므로 트리의 깊이는 default 값에 비해 얕아진다.
# DecisionTree Classifier 생성 및 min_samples_split 10 셋팅
dt_clf = DecisionTreeClassifier(random_state=156, min_samples_split=10)▶ Out
5. 하이퍼 파라미터 - min_samples_leaf
말단 노드(Leaf)가 되기 위한 최소한의 샘플 데이터 수를 설정하기 위한 값이다.
min_samples_split와 유사하게 과적합 제어 용도이다. 그러나 비대칭적 데이터의 경우 특정 클래스의 데이터가 극도로 적을 수 있으므로 이러한 경우에는 작게 설정해야한다.
min_samples_split 기준에 맞아서 분할을 하더라도 min_samples_leaf 기준에 맞지 않아서 leaf 노드를 만들 수 없으면 최종 leaf 노드로 생성할 수 없다.
만약, min_samples_split = 6, min_samples_leaf가 4인 경우를 살펴보자. 6개의 sample로 node에 개별 클랙스 값이 각각 3개씩 들어가 있으면 min_samples_leaf의 최소 개수가 4이기 때문에 leaf node로 만들 수 없어서 분할 할 수 없다.
⎷ 실습
위의 min_samples_split은 10으로 유지하고 min_samples_leaf를 15로 변경한 경우 기존에 samples =3인 leaf 노드는 생성 되지 못한 것을 확인할 수 있다.
# DecisionTree Classifier 생성
dt_clf = DecisionTreeClassifier(random_state=156, min_samples_split=10, min_samples_leaf=15)▶ Out
6. 하이퍼 파라미터 - max_leaf_nodes
말단 노드(leaf)의 최대 개수이다.
⎷ 실습
위의 max_leaf_nodes 2로 지정하면 2개의 노드로만 구성된다.
# DecisionTree Classifier 생성
dt_clf = DecisionTreeClassifier(random_state=156, max_leaf_nodes=2)▶ Out
'ML > 분류(Classification)' 카테고리의 다른 글
| 사용자 행동 인식(Human Activity Recognition) 데이터 세트를 활용한 결정트리 실습 (0) | 2024.05.22 |
|---|---|
| 결정트리의 과적합(Overfitting) (0) | 2024.05.07 |
| 특성 중요도(feature_importances_) (0) | 2024.04.22 |
| 결정 트리란? 엔트로피, 정보이득, 그리고 지니계수 (0) | 2024.04.02 |
| 분류(Classification)와 대표적인 알고리즘 (0) | 2024.04.02 |