GridSearchCV이란?
1. GridSearchCV이란?
GridSearchCV란 사이킷런에서 교차 검증을 기반으로 앞서 이야기했던 하이퍼파라미터의 최적 값을 찾을 수 있는 함수이다.
만약 GridSearchCV 클래스를 사용하지 않을 경우 반복문을 여러번 수행하면서 하이퍼파라미터 값을 찾아야하고 이는 찾아야할 값들이 많아질 경우 복잡도와 가독성이 매우 떨어지게 된다.
GridSearchCV 함수를 간단하게 살펴보면 다음과 같다.
- estimator : 예측기 객체 (Classifier, Regressor, Pipeline 등)
- param_grid : 사용할 파라미터가 정의된 dictionary
- refit : 가장 좋은 파라미터 값으로 자동 재학습 처리(default True)
- cv : 교차검증 개수
2. GridSearchCV 예시
앞서 예시로 살펴본 붓꽃 데이터를 통해 GridSerchCV를 통해 하이퍼파라미터를 찾아본다.
먼저 붓꽃데이터를 이용해 학습데이터와 테스트 데이터를 분리한다.
그리고 GridSearchCV 함수에서 사용할 하이퍼파라미터를 설정한다. 이 파라미터는 리스트 형태의 dictionary 설정 해줘야한다.
Decision Tree Classifier의 하이퍼파라미터는 여러가지가 존재하지만 이 예제에서는 max_depth와 min_samples_split 2개의 최적화된 값만 찾아본다.
- min_samples_split
- 노드를 분할하기 위한 최소한의 샘플 데이터수이다.
- 작게 설정할수록 분할 노드가 많아져서 과적합 가능성이 증가한다. - max_depth :
트리의 최대 깊이 값이다. 클래스 값이 결정될 때까지 분할하거나 데이터 개수가 min_samples_split보다 작아질때 까지 분할한다.
깊이가 깊어지면 과적합될 수 있다.
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.metrics import accuracy_score
# 데이터를 로딩하고 학습데이타와 테스트 데이터 분리
iris = load_iris()
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target,
test_size=0.2, random_state=121)
dtree = DecisionTreeClassifier()
### parameter 들을 dictionary 형태로 설정
parameters = {'max_depth':[1, 2, 3], 'min_samples_split':[2,3]}
GridSearchCV의 결과는 cv_results_ 라는 딕셔너리로 저장이 된다.
import pandas as pd
grid_dtree = GridSearchCV(dtree, param_grid=parameters, cv=3, refit=True, return_train_score=True)
# 붓꽃 Train 데이터로 param_grid의 하이퍼 파라미터들을 순차적으로 학습/평가 .
grid_dtree.fit(X_train, y_train)
grid_dtree.cv_results_▶ Out
{'mean_fit_time': array([0.00079163, 0.00045864, 0.00050839, 0.00036724, 0.00039697,
0.00034221]),
'std_fit_time': array([2.71542562e-04, 5.56111300e-05, 4.46385689e-05, 2.16461079e-05,
5.40206205e-05, 7.96554376e-06]),
'mean_score_time': array([0.00036073, 0.00024597, 0.00026457, 0.00017436, 0.00021664,
0.00015926]),
'std_score_time': array([9.22685035e-05, 3.75887304e-05, 6.17979036e-05, 1.42311906e-05,
5.18870748e-05, 2.72535137e-06]),
'param_max_depth': masked_array(data=[1, 1, 2, 2, 3, 3],
mask=[False, False, False, False, False, False],
fill_value='?',
dtype=object),
'param_min_samples_split': masked_array(data=[2, 3, 2, 3, 2, 3],
mask=[False, False, False, False, False, False],
fill_value='?',
dtype=object),
'params': [{'max_depth': 1, 'min_samples_split': 2},
{'max_depth': 1, 'min_samples_split': 3},
{'max_depth': 2, 'min_samples_split': 2},
{'max_depth': 2, 'min_samples_split': 3},
{'max_depth': 3, 'min_samples_split': 2},
{'max_depth': 3, 'min_samples_split': 3}],
'split0_test_score': array([0.7 , 0.7 , 0.925, 0.925, 0.975, 0.975]),
'split1_test_score': array([0.7, 0.7, 1. , 1. , 1. , 1. ]),
'split2_test_score': array([0.7 , 0.7 , 0.95, 0.95, 0.95, 0.95]),
'mean_test_score': array([0.7 , 0.7 , 0.95833333, 0.95833333, 0.975 ,
0.975 ]),
'std_test_score': array([1.11022302e-16, 1.11022302e-16, 3.11804782e-02, 3.11804782e-02,
2.04124145e-02, 2.04124145e-02]),
'rank_test_score': array([5, 5, 3, 3, 1, 1], dtype=int32),
'split0_train_score': array([0.7 , 0.7 , 0.975 , 0.975 , 0.9875, 0.9875]),
'split1_train_score': array([0.7 , 0.7 , 0.9375, 0.9375, 0.9625, 0.9625]),
'split2_train_score': array([0.7 , 0.7 , 0.9625, 0.9625, 0.9875, 0.9875]),
'mean_train_score': array([0.7 , 0.7 , 0.95833333, 0.95833333, 0.97916667,
0.97916667]),
'std_train_score': array([1.11022302e-16, 1.11022302e-16, 1.55902391e-02, 1.55902391e-02,
1.17851130e-02, 1.17851130e-02])}
GridSearchCV의 결과를 조금 더 쉽게 보기 위해 DataFrame으로 변환하여 살펴보면 다음과 같다.
변환을 위한 컬럼들은 다음과 같다
- params : 앞에서 선언한 parameter들의 조합
- mean_test_score : split{0}_test_score들의 평균 테스트 점수
- rank_test_score : mean_test_score들의 순위 값
- split{0}_test_score : K Fold로 교차검증할 때 split된 검증데이터로 테스트를 진행한 평가 점수
3 Fold일 경우 1/3 검증데이터 split되므로 split0, split1, split2가 생성된다.
# GridSearchCV 결과는 cv_results_ 라는 딕셔너리로 저장됨. 이를 DataFrame으로 변환
scores_df = pd.DataFrame(grid_dtree.cv_results_)
scores_df[['params', 'mean_test_score', 'rank_test_score',
'split0_test_score', 'split1_test_score', 'split2_test_score']]▶ Out
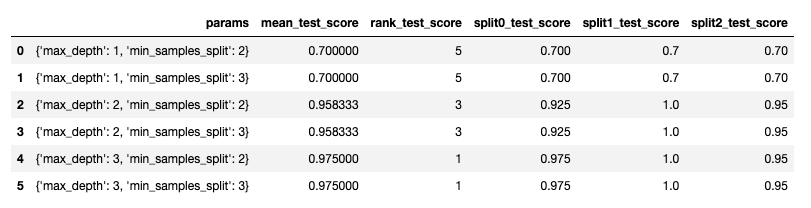
GridSearchCV함수를 통해 최적화된 하이퍼파라미터는 'best_params_' 값을 통해 확인할 수 있고 학습된 예측 정확도도 구할 수 있다.
print('GridSearchCV 최적 파라미터:', grid_dtree.best_params_)
print('GridSearchCV 최고 정확도: {0:.4f}'.format(grid_dtree.best_score_))
# refit=True로 설정된 GridSearchCV 객체가 fit()을 수행 시 학습이 완료된 Estimator를 내포하고 있으므로 predict()를 통해 예측도 가능.
pred = grid_dtree.predict(X_test)
print('테스트 데이터 세트 정확도: {0:.4f}'.format(accuracy_score(y_test,pred)))▶ Out
GridSearchCV 최적 파라미터: {'max_depth': 3, 'min_samples_split': 2}
GridSearchCV 최고 정확도: 0.9750
테스트 데이터 세트 정확도: 0.9667
GridSearchCV의 refit으로 이미 학습이 된 estimator 반환, 이를 통해 예측 정확도를 구할 수 있으며 앞서 GridSearchCV를 통해 구해진 정확도와 동일한 결과가 나오는걸 확인할 수 있다.
estimator = grid_dtree.best_estimator_
# GridSearchCV의 best_estimator_는 이미 최적 하이퍼 파라미터로 학습이 됨
pred = estimator.predict(X_test)
print('테스트 데이터 세트 정확도: {0:.4f}'.format(accuracy_score(y_test,pred)))▶ Out
테스트 데이터 세트 정확도: 0.9667