피마 인디언 당뇨병 데이터로 머신러닝 평가하기
1. 피마 인디어 당뇨병 데이터 분석
Kaggle에서 제공하는 피마 인디어 당뇨병 데이터셋을 이용하여 피마 인디언의 당뇨병 데이터를 분석하고 발병 확률과 평가수치를 적용하여 살펴본다.
Kaggle에서 제공하는 피마 인디어 당뇨병 데이터셋을 다운로드한 후 데이터를 살펴보면 다음과 같다.
- Pregnancies: 임신 횟수
- Glucose: 포도당 부하 검사 수치
- BloodPressure: 혈압(mm Hg)
- SkinThickness: 팔 삼두근 뒤쪽의 피하지방 측정값(mm)
- Insulin: 혈청 인슐린(mu U/ml)
- BMI: 체질량지수(체중(kg)/(키(m))^2)
- DiabetesPedigreeFunction: 당뇨 내력 가중치 값
- Age: 나이
- Outcome: 클래스 결정 값(0또는 1)
768개의 데이터 중 Negative 값(0)이 500개, Positive 값(1)이 268개이다. 전체 데이터의 약 65%가 Neagative임을 알 수 있다.
import numpy as np
import pandas as pd
diabetes_data = pd.read_csv('diabetes.csv')
diabetes_data.head(3)▶ Out
0 500
1 268
Name: Outcome, dtype: int64
info() 메소드를 통해 각 필드별 데이터 타입과 NULL값이 존재하는지를 체크해보자.
NULL 값이 존재하는 필드는 없으며 모두 int와 float타입을 가지고 있으므로 별도로 데이터 전처리를 위한 프로세스는 필요하지 않다.
diabetes_data.info( )▶ Out
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 768 entries, 0 to 767
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Pregnancies 768 non-null int64
1 Glucose 768 non-null int64
2 BloodPressure 768 non-null int64
3 SkinThickness 768 non-null int64
4 Insulin 768 non-null int64
5 BMI 768 non-null float64
6 DiabetesPedigreeFunction 768 non-null float64
7 Age 768 non-null int64
8 Outcome 768 non-null int64
dtypes: float64(2), int64(7)
memory usage: 54.1 KB
2. 오차행렬, 정확도, 정밀도, 재현율, f1_score, ROC, AUC
오차행렬, 정확도, 정밀도, 재현율, f1_score, ROC, AUC을 한번에 가져오기 위한 get_clf_eval() 함수를 생성해준다.
from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score
from sklearn.metrics import f1_score, confusion_matrix, precision_recall_curve, roc_curve
from sklearn.preprocessing import StandardScaler
# get_clf_eval() 함수
def get_clf_eval(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix( y_test, pred)
accuracy = accuracy_score(y_test , pred)
precision = precision_score(y_test , pred)
recall = recall_score(y_test , pred)
f1 = f1_score(y_test,pred)
# ROC-AUC 추가
roc_auc = roc_auc_score(y_test, pred_proba)
print('오차 행렬')
print(confusion)
# ROC-AUC print 추가
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f},\
F1: {3:.4f}, AUC:{4:.4f}'.format(accuracy, precision, recall, f1, roc_auc))
학습 데이터와 테스트 데이터 세트로 분리 후 트레이닝 학습을 위해 로지스틱 회귀로 학습,예측 및 평가를 수행한다.
그리고 위에서 생성한 get_clf_e val() 메소드를 호출하여 오차행렬, 정확도, 정밀도, 재현율, f1_score, ROC, AUC 값을 가져온다.
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# 피처 데이터 세트 X, 레이블 데이터 세트 y를 추출.
# 맨 끝이 Outcome 컬럼으로 레이블 값임. 컬럼 위치 -1을 이용해 추출
X = diabetes_data.iloc[:, :-1]
y = diabetes_data.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=156, stratify=y)
# 로지스틱 회귀로 학습,예측 및 평가 수행.
lr_clf = LogisticRegression(solver='liblinear')
lr_clf.fit(X_train, y_train)
pred = lr_clf.predict(X_test)
pred_proba = lr_clf.predict_proba(X_test)[:, 1]
get_clf_eval(y_test , pred, pred_proba)▶ Out
오차 행렬
[[87 13]
[22 32]]
정확도: 0.7727, 정밀도: 0.7111, 재현율: 0.5926, F1: 0.6465, AUC:0.8083
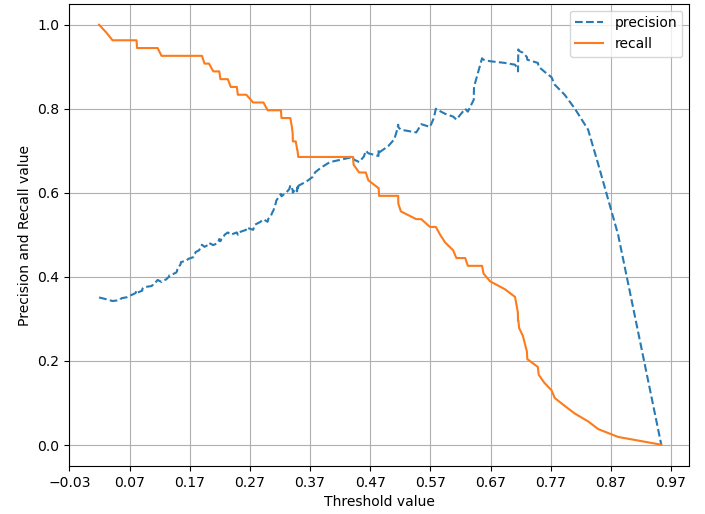
그리고 precision - recall 곡선 그림의 결과 값도 출력해본다. 최적값의 threshold 값이 대략 0.4 정도 임을 확인할 수 있다.
위의 결과를 보니 재현율은 0.59로 그리 높지 않은 것을 확인할 수 있다.
import matplotlib.pyplot as plt
%matplotlib inline
def precision_recall_curve_plot(y_test=None, pred_proba_c1=None):
# threshold ndarray와 이 threshold에 따른 정밀도, 재현율 ndarray 추출.
precisions, recalls, thresholds = precision_recall_curve( y_test, pred_proba_c1)
# X축을 threshold값으로, Y축은 정밀도, 재현율 값으로 각각 Plot 수행. 정밀도는 점선으로 표시
plt.figure(figsize=(8,6))
threshold_boundary = thresholds.shape[0]
plt.plot(thresholds, precisions[0:threshold_boundary], linestyle='--', label='precision')
plt.plot(thresholds, recalls[0:threshold_boundary],label='recall')
# threshold 값 X 축의 Scale을 0.1 단위로 변경
start, end = plt.xlim()
plt.xticks(np.round(np.arange(start, end, 0.1),2))
# x축, y축 label과 legend, 그리고 grid 설정
plt.xlabel('Threshold value'); plt.ylabel('Precision and Recall value')
plt.legend(); plt.grid()
plt.show()
pred_proba_c1 = lr_clf.predict_proba(X_test)[:, 1]
precision_recall_curve_plot(y_test, pred_proba_c1)▶ Out
3. 재현율을 높이기 위한 데이터 분석 및 재학습과 예측
2번 과정에서 진행했던 예측에서는 재현율이 0.59로 높지 않는 것을 확인할 수 있었다.
재현율을 높이기 위해 데이터를 분석을 해보자.
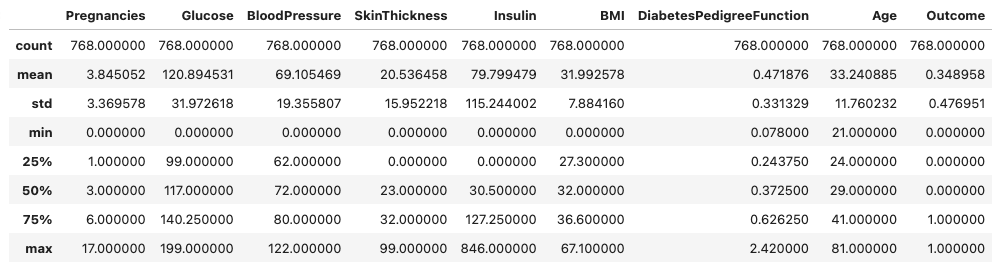
describe() 메소드를 호출하여 각 필드별 데이터 요약 내용을 살펴본다.
포도당 수치, 혈압 등 0 값이 존재하는 필드들이 있는 것을 확인할 수 있고, 실제로 0이 들어간 데이터는 잘못된 값임을 알 수 있다.
diabetes_data.describe()▶ Out
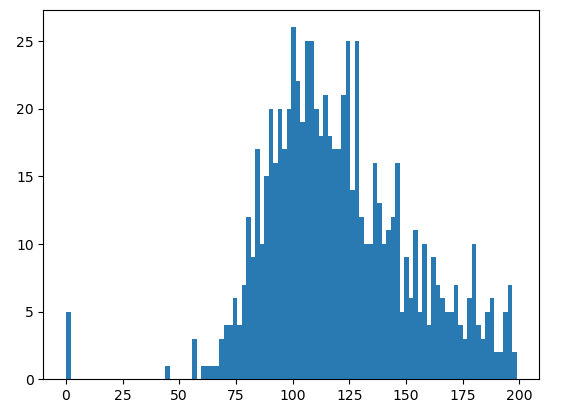
추가로 0이 존재하는 여러 필드 중에서 샘플로 Glucose(포도당 부하 검사 수치)이 가지고 있는 값들의 분포도를 확인해보자.
plt.hist(diabetes_data['Glucose'], bins=100)
plt.show()▶ Out
0값을 가지고 있는 여러 필드에서 0값이 전체 데이터 중 차지하고 있는 비중을 확인하기 위해 백분율을 계산한다.
# 0값을 검사할 피처명 리스트 객체 설정
zero_features = ['Glucose', 'BloodPressure','SkinThickness','Insulin','BMI']
# 전체 데이터 건수
total_count = diabetes_data['Glucose'].count()
# 피처별로 반복 하면서 데이터 값이 0 인 데이터 건수 추출하고, 퍼센트 계산
for feature in zero_features:
zero_count = diabetes_data[diabetes_data[feature] == 0][feature].count()
print('{0} 0 건수는 {1}, 퍼센트는 {2:.2f} %'.format(feature, zero_count, 100*zero_count/total_count))▶ Out
Glucose 0 건수는 5, 퍼센트는 0.65 %
BloodPressure 0 건수는 35, 퍼센트는 4.56 %
SkinThickness 0 건수는 227, 퍼센트는 29.56 %
Insulin 0 건수는 374, 퍼센트는 48.70 %
BMI 0 건수는 11, 퍼센트는 1.43 %
0을 가지고 있는 필드들의 값을 보정하기 위해 각 필드들의 0값을 평균값으로 대체해준다.
diabetes_data[zero_features] = diabetes_data[zero_features].replace(0, diabetes_data[zero_features].mean())
보정된 데이터 세트를 가지고 다시 한번 학습과 예측을 수행한다.
데이터를 보정한 이후 재현율이 조금 더 좋아지는 것을 확인할 수 있다.
X = diabetes_data.iloc[:, :-1]
y = diabetes_data.iloc[:, -1]
# StandardScaler 클래스를 이용해 피처 데이터 세트에 일괄적으로 스케일링 적용
scaler = StandardScaler( )
X_scaled = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size = 0.2, random_state = 156, stratify=y)
# 로지스틱 회귀로 학습, 예측 및 평가 수행.
lr_clf = LogisticRegression(solver='liblinear')
lr_clf.fit(X_train , y_train)
pred = lr_clf.predict(X_test)
pred_proba = lr_clf.predict_proba(X_test)[:, 1]
get_clf_eval(y_test , pred, pred_proba)▶ Out
오차 행렬
[[90 10]
[21 33]]
정확도: 0.7987, 정밀도: 0.7674, 재현율: 0.6111, F1: 0.6804, AUC:0.8433
이제 분류 임계값(thresholds) 값을 변경하면서 재현율의 변화를 살펴보자.
임계값을 0.3~ 0.5까지 각각 0.3씩 증가하는 리스트를 만들어준다. 루프를 돌면서 리스트에 있는 임계값를 각각 적용하여 재현율의 변화를 살펴보자.
결과를 살펴보면 재현율이 높더라도 정밀도가 너무 떨어지는 것은 좋지 않다. 0.48의 경우 재현율은 낮으나 정밀도의 차이가 0.04로 재현율의 차이 0.02보다 더 크므로 0.48이 조금 더 좋은 수치로 볼 수 있다.
| 0.45 | 0.48 | 0.45 기준 차이 | |
| 재현율 | 0.6667 | 0.6481 | +0.02 |
| 정밀도 | 0.7059 | 0.7447 | -0.04 |
from sklearn.preprocessing import Binarizer
def get_eval_by_threshold(y_test, pred_proba_c1, thresholds):
# thresholds 리스트 객체내의 값을 차례로 iteration하면서 Evaluation 수행.
for custom_threshold in thresholds:
binarizer = Binarizer(threshold=custom_threshold).fit(pred_proba_c1)
custom_predict = binarizer.transform(pred_proba_c1)
print('임계값:', custom_threshold)
get_clf_eval(y_test, custom_predict, pred_proba_c1)
thresholds = [0.3 , 0.33 ,0.36,0.39, 0.42 , 0.45 ,0.48, 0.50]
pred_proba = lr_clf.predict_proba(X_test)
get_eval_by_threshold(y_test, pred_proba[:,1].reshape(-1,1), thresholds )▶ Out
임계값: 0.3
오차 행렬
[[65 35]
[11 43]]
정확도: 0.7013, 정밀도: 0.5513, 재현율: 0.7963, F1: 0.6515, AUC:0.8433
임계값: 0.33
오차 행렬
[[71 29]
[11 43]]
정확도: 0.7403, 정밀도: 0.5972, 재현율: 0.7963, F1: 0.6825, AUC:0.8433
임계값: 0.36
오차 행렬
[[76 24]
[15 39]]
정확도: 0.7468, 정밀도: 0.6190, 재현율: 0.7222, F1: 0.6667, AUC:0.8433
임계값: 0.39
오차 행렬
[[78 22]
[16 38]]
정확도: 0.7532, 정밀도: 0.6333, 재현율: 0.7037, F1: 0.6667, AUC:0.8433
임계값: 0.42
오차 행렬
[[84 16]
[18 36]]
정확도: 0.7792, 정밀도: 0.6923, 재현율: 0.6667, F1: 0.6792, AUC:0.8433
임계값: 0.45
오차 행렬
[[85 15]
[18 36]]
정확도: 0.7857, 정밀도: 0.7059, 재현율: 0.6667, F1: 0.6857, AUC:0.8433
임계값: 0.48
오차 행렬
[[88 12]
[19 35]]
정확도: 0.7987, 정밀도: 0.7447, 재현율: 0.6481, F1: 0.6931, AUC:0.8433
임계값: 0.5
오차 행렬
[[90 10]
[21 33]]
정확도: 0.7987, 정밀도: 0.7674, 재현율: 0.6111, F1: 0.6804, AUC:0.8433
임계값 0.48로 설장하여 학습과 예측을 하면 아래와 같은 결과를 확인할 수 있다.
# 임곗값를 0.48로 설정한 Binarizer 생성
binarizer = Binarizer(threshold=0.48)
# 위에서 구한 lr_clf의 predict_proba() 예측 확률 array에서 1에 해당하는 컬럼값을 Binarizer변환.
pred_th_048 = binarizer.fit_transform(pred_proba[:, 1].reshape(-1,1))
get_clf_eval(y_test , pred_th_048, pred_proba[:, 1])▶ Out
오차 행렬
[[88 12]
[19 35]]
정확도: 0.7987, 정밀도: 0.7447, 재현율: 0.6481, F1: 0.6931, AUC:0.843