결정 트리란? 엔트로피, 정보이득, 그리고 지니계수
1. 결정 트리란?
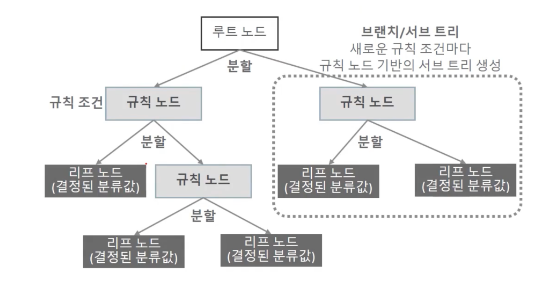
결정 트리는 데이터에 있는 규칙을 학습을 통하여 자동으로 찾아내 트리(Tree) 기반의 분류 교칙을 만들게 된다. 마치 스무고개를 하듯이 '예/아니오' 질문을 이어가며 학습하게 된다.
결정트리는 '데이터의 어떤 기준을 바탕으로 규칙을 만들어야 가장 효율적인 분류가 될것인가'가 알고리즘의 성능을 좌우하게 된다.
결정 트리는 매우 쉽고 유연하게 적용될 수 있고 데이터의 스케일링이나 정규화 등의 사전 가공의 영향이 매우 적다는 장점이 있다.
그러나 단점으로는 예측 성능을 향상하기 위해서는 복잡한 규칙 구조를 가져야하며 이로 안한 과적합(Overfitting)이 발생해 도리어 예측 성능이 저하될 수 있다.
이러한 단점이 앙상블 기법에서는 장점으로 작용한다. 앙상블은 매우 많은 여러개의 약한 학습기(예측 성능이 떨이지는 학습 알고리즘)를 결합하여 확률적 보완과 오류가 발생한 부분에 대한 가중치를 계속 업데이틀 한다. 그리고 이를 통해 예측 성능을 향상시키게 되는데 결정트리가 좋은 약한 학습기가 되기 때문이다.(GBM, XGBoost, LightGBM 등)
2. 엔트로피와 정보 이득, 그리고 지니 계수
엔트로피는 주어진 데이터 집합의 혼잡도를 의미한다. 서로 다른 값이 섞여 있으면 엔트로피가 높고, 같은 값이 섞여 있으면 엔트로피가 낮다. 즉, 데이터를 잘 구분할 수 없을 수록 엔트로피는 커지게 된다.
정보 이득은 엔트로피라는 개념을 기반으로 하는데 정보 이득 지수는 1에서 엔트로피 지수를 뺀 값이다. 결정 트리는 정보 이득 지수로 분할 기준을 정하게 되는데 정보 이득이 높은 속성을 기준으로 분할한다.
지니 계수는 원래 경제학에서 불평등 지수를 나타낼 때 사용하는 계수이다. 0일 때 가장 평등하고 1로 갈수록 불평등하다. 머신런닝에서 적용될 때는 지니 계수가 낮을 수록 데이터의 균일도가 높은 것으로 해석되며 계수가 낮은 속성을 기준으로 분할하게 된다.
결정 트리의 규칙 노드 생성 프로세스는 다음과 같다.
