
빅데이터, 분산처리 관련 기술들을 공부하다보니 스파크란 프레임워크를 알게되었고 이번 기회에 내용을 정리해보도록 한다.
1.스파크란? & 등장배경
스파크를 한마디로 정의하면 빅데이터처리를 위한 오픈소스 분산처리 플랫폼, 또는 빅데이터 분산처리엔진이다.
스파크가 나오게 된 배경으로는 하둡의 단점을 보완하기 위해서 탄생하였다. HDFS는 DISK I/O를 기반으로 동작한다. 이는 하둡의 처리 속도를 느리게 하는 요인이었고 실시간성 데이터에 대한 니즈를 증가하는 상황에서 충족하지 못하는 상황이 발생하였다.
스파크의 경우 메모리로부터 map/reduce할 데이터를 불러오고 결과도 메모리에 저장한다. 그렇기에 속도도 하둡에 비해 1000배 정도 빠르고 배치 분석 뿐만 아니라, 스트리밍 데이터 양쪽 분석 모두 지원함에 따라 스파크를 점점 선호하게 되었다.
2. 스파크의 구조
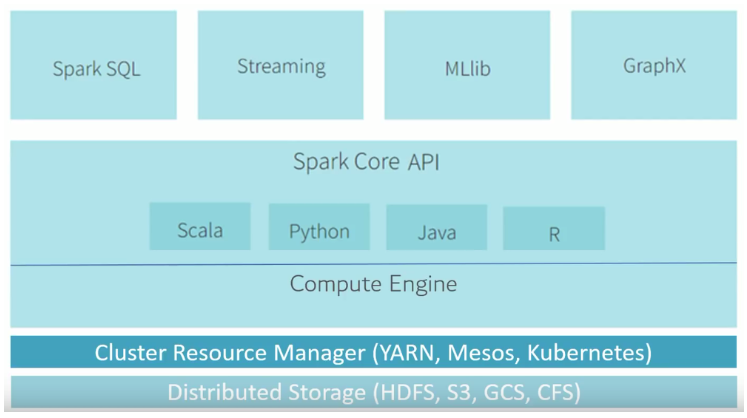
스파크는 분산 처리 엔진이지만 자원 스케쥴링 기능이 없다. 그렇기에 자원 스케쥴링등의 Resource를 관리할 수 있는 YARN, kubernetes, Mesos등을 사용한다.
Spark Core는 스프크의 언어 API는 다양한 언어를 지원하고 SQL과 실시간 데이터 처리를 지원하는 Spark Streaming, 머신러닝을 지원하는 MlLib등 다양하고 넒은 범위의 라이브러리가 있고 계속 확장하고 있다.
3. Spark Cluster & Spark Applicaiton
스파크의 모듈을 크게 보면 컴퓨터 Cluster의 리소스를 관리하는 Cluster Manager와 그리고 그 위에서 동작하는 프로그램인 Spark Application으로 구분된다.
클러스터란 무엇일까? 간단하게 말하면 여러 자원들의 자원을 가지고 하나의 컴퓨터처럼 사용하는 것이라고 생각하면 된다. 보통 Master-slave구조로 되어 있다.
스파크는 클러스터 구조로 되어 있고 클러스터 내에 여러 자원들이 논리적으로 나뉘어져 있다. 이렇게 나뉘어지 자원들은 스파크의 Cluster Manager가 담당한다. 스파크의 Cluster Manager로는 크게 Spark에 built-in된 기본 모듈 Spark Standalone, Hadoop에서 사용되는 Yarn, UC Berkeley에서 개발한 Mesos, Kubernetes가 사용된다.
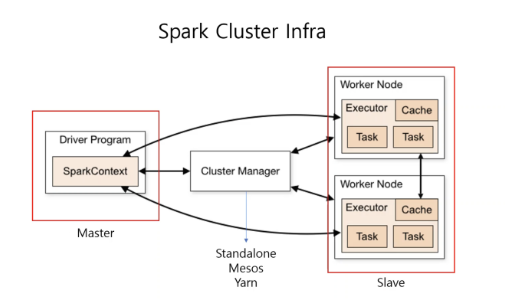
위의 이미지와 같이 Spark Clsuter Infra는 master - Cluster Manager - Slave 형태이다.
Cluster Manager는 Master-Slave의 각자 할당받은 리소스(CPU, 메모리)를 관리한다.
SparkContext, 즉 Master는 Driver Program이라고 부른다. 스파크의 애플리케이션 의 정보를 유지, 관리하고 전반적인 Executor 프로세스 작업에 관련된 스케줄링 역할을 수행한다.
Worker Node는 클러스터에서 애플리케이션을 실행하는 Node를 의미한다. 각 Worker Node안에는 Executor가 존재하며 Executor는 등록된 여러개의 Task(실제 작업)들을 동작시키고 in memory방식이나 Disk에 저장된 데이터를 관리한다.
4. 스파크의 기본 동작 원리
분석을 위해 분석 프로그램을 스파크 클러스터에 실행하게 되면 하나의 JOB이 생성된다.
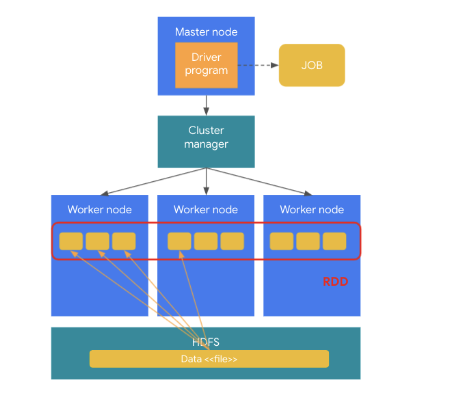
생성된 JOB이 외부저장소(HDFS, DB)로부터 데이터를 로딩을 하게 되면 로딩된 데이터가 Worker Node로 로딩이 된다. 이 때 로딩된 데이터는 한개의 서버가 아닌 여러 서버의 메모리에 분산되어 로딩이 되고 이 저장된 데이터 객체를 RDD라고 한다.
로딩된 데이터가 애플리케이션 로직에 의해 실행이 되는데 하나의 JOB이 여러 Wordker Node에 분산된 데이트를 분산되어 실행을 하게 된다. 즉, 하나의 JOB이 여러개의 Task로 분리되어 실행이 된다.
'분산처리 > Spark' 카테고리의 다른 글
| Spark History Server 오류 (0) | 2022.07.31 |
|---|---|
| Apache Spark 설치 및 예제 실습- macOS (0) | 2022.07.30 |