
2022.07.29 - [InfraStructure] - 스파크란? -기본
스파크란? -기본
빅데이터, 분산처리 관련 기술들을 공부하다보니 스파크란 프레임워크를 알게되었고 이번 기회에 내용을 정리해보도록 한다. 1.스파크란? & 등장배경 스파크를 한마디로 정의하면 빅데이터처리
yarisong.tistory.com
지난 포스팅을 통해 스파크에 대해 알아보았고 이제 설치를 통해 이해도를 높여보도록 한다.
1. Spark 설치
Spark 설치를 위해서는 홈페이지에서 다운받아 설치하는 방법과 Homebrew를 사용하는 방법 2가지가 있다. homebrew가 보통 편하기에 이 포스팅에서는 homebrew를 통해 설치를 진행한다.
터미널을 열어 아래와 같이 명령어를 실행한다.
$ brew install apache-spark
설치가 완료되고 나면 스파크 쉘 실행 스크립트를 실행한다.
$ spark-shell
스파크가 정상 실행되고 나면 아래와 같이 welcome to Spark가 보이게 된다.
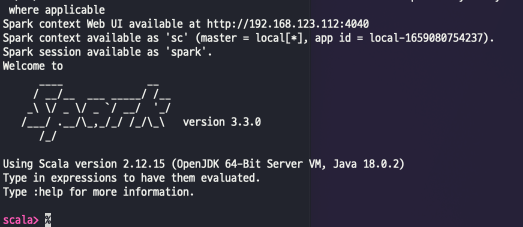
2. Spark 설정 및 실행하기
Spark 마스터 실행한다. 마스터 실행 시 사용되는 기본 포트는 7077번 포트가 사용된다.
$ cd /usr/local/Cellar/apache-spark/3.3.0/libexec/sbin
$ ./start-master.sh
만약 마스터를 실행 중에 "BindException: Can't assign requested address" 오류가 발생하는 경우가 있다.
이런 경우 아래와 같이 조치한다.
#1. hostname 조회
$ hostname
#2. hosts 파일에 hostname 등록
$ sudu vim /etc/hosts
##
# Host Database
#
# localhost is used to configure the loopback interface
# when the system is booting. Do not change this entry.
##
127.0.0.1 localhost
#1번에서 조회한 사용자 hostname등록
127.0.0.1 <사용자_hostname>
Master를 기동하고 나서 Worker를 실행하기 앞서 인스턴스 환경 설정을 해줘야한다.
$ cd /usr/local/Cellar/apache-spark/3.3.0/libexec/conf
cp spark-env.sh.template spark-env.sh
복사한 spark-env.sh 파일 내에 Worker로 돌릴 인스턴스의 개수를 지정 후 저장한다.
export SPARK_WORKER_INSTANCES=3
인스턴스의 개수 조정이 완료되고 나서 worker를 실행해준다. 실행 시 옵션으로는 사용할 메모리와 코어 개수를 지정할 수 있다.
$ cd /usr/local/Cellar/apache-spark/3.3.0/libexec/sbin
$ ./start-slave.sh spark://<사용자_hostname>:7077
# -m 은 워커가 사용할 메모리 지정
# -c 은 워커가 사용할 코어 개수 지정
# ./start-slave.sh spark://<사용자_hostname>:7077 -m 512M -c 1
슬래이브를 실행 후 spark 콘솔인 http://localhost:8080/에 접속하면 설정한 worker 숫자만큼 생성됨을 확인할 수 있다.
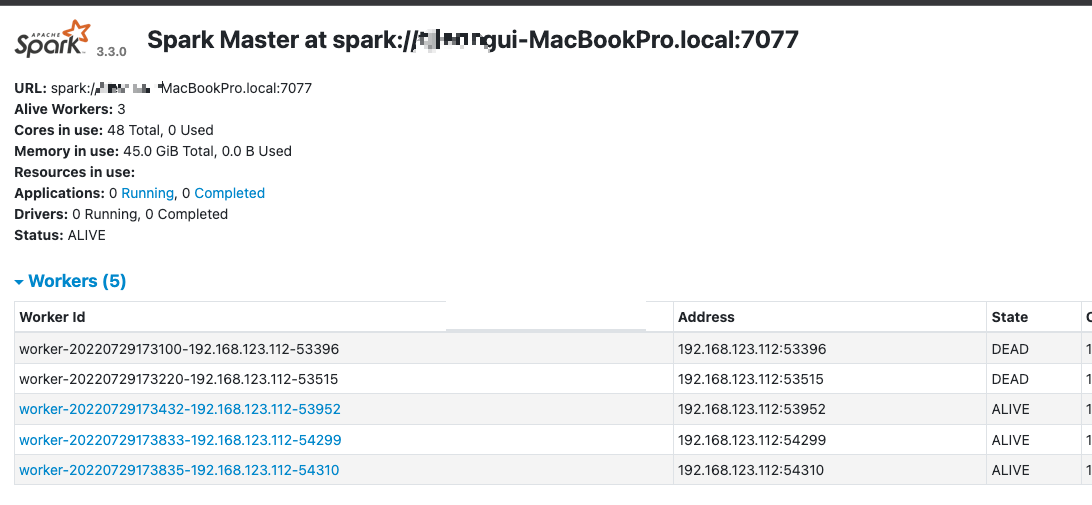
3. Spark 간단한 예제 실습
간단한 실습을 하기 위해 먼저 master 서버에 작업을 올린다.
콘솔 창을 오픈 하고 아래와 같이 spark-shell을 실행해준다.
spark-shell --master spark://<사용자_hostname>:7077
정상적으로 오픈이 되었다면 "welcome to spark" 문구가 보이게 된다.
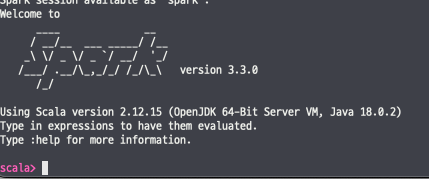
또한, 스파크 웹 콘솔 화면에서도 Running Application List에 Spark shell이 올라오게 된다.

아래와 같은 텍스트 파일에서 lines.count() 출력하는 간단한 실습이다.
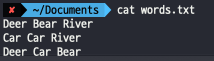
테스트 방법은 간단하다. 텍스트 파일을 불러와서 라인수를 조회하는 명령어를 수행하면 된다.
scala> var lines = sc.textFile("/Users/user/Documents/words.txt")
lines: org.apache.spark.rdd.RDD[String] = /Users/user/Documents/words.txt MapPartitionsRDD[1] at textFile at <console>:23
scala> lines.count()
res0: Long = 4
'분산처리 > Spark' 카테고리의 다른 글
| Spark History Server 오류 (0) | 2022.07.31 |
|---|---|
| 스파크란? -기본 (0) | 2022.07.29 |
2022.07.29 - [InfraStructure] - 스파크란? -기본
스파크란? -기본
빅데이터, 분산처리 관련 기술들을 공부하다보니 스파크란 프레임워크를 알게되었고 이번 기회에 내용을 정리해보도록 한다. 1.스파크란? & 등장배경 스파크를 한마디로 정의하면 빅데이터처리
yarisong.tistory.com
지난 포스팅을 통해 스파크에 대해 알아보았고 이제 설치를 통해 이해도를 높여보도록 한다.
1. Spark 설치
Spark 설치를 위해서는 홈페이지에서 다운받아 설치하는 방법과 Homebrew를 사용하는 방법 2가지가 있다. homebrew가 보통 편하기에 이 포스팅에서는 homebrew를 통해 설치를 진행한다.
터미널을 열어 아래와 같이 명령어를 실행한다.
$ brew install apache-spark
설치가 완료되고 나면 스파크 쉘 실행 스크립트를 실행한다.
$ spark-shell
스파크가 정상 실행되고 나면 아래와 같이 welcome to Spark가 보이게 된다.
2. Spark 설정 및 실행하기
Spark 마스터 실행한다. 마스터 실행 시 사용되는 기본 포트는 7077번 포트가 사용된다.
$ cd /usr/local/Cellar/apache-spark/3.3.0/libexec/sbin
$ ./start-master.sh
만약 마스터를 실행 중에 "BindException: Can't assign requested address" 오류가 발생하는 경우가 있다.
이런 경우 아래와 같이 조치한다.
#1. hostname 조회
$ hostname
#2. hosts 파일에 hostname 등록
$ sudu vim /etc/hosts
##
# Host Database
#
# localhost is used to configure the loopback interface
# when the system is booting. Do not change this entry.
##
127.0.0.1 localhost
#1번에서 조회한 사용자 hostname등록
127.0.0.1 <사용자_hostname>
Master를 기동하고 나서 Worker를 실행하기 앞서 인스턴스 환경 설정을 해줘야한다.
$ cd /usr/local/Cellar/apache-spark/3.3.0/libexec/conf
cp spark-env.sh.template spark-env.sh
복사한 spark-env.sh 파일 내에 Worker로 돌릴 인스턴스의 개수를 지정 후 저장한다.
export SPARK_WORKER_INSTANCES=3
인스턴스의 개수 조정이 완료되고 나서 worker를 실행해준다. 실행 시 옵션으로는 사용할 메모리와 코어 개수를 지정할 수 있다.
$ cd /usr/local/Cellar/apache-spark/3.3.0/libexec/sbin
$ ./start-slave.sh spark://<사용자_hostname>:7077
# -m 은 워커가 사용할 메모리 지정
# -c 은 워커가 사용할 코어 개수 지정
# ./start-slave.sh spark://<사용자_hostname>:7077 -m 512M -c 1
슬래이브를 실행 후 spark 콘솔인 http://localhost:8080/에 접속하면 설정한 worker 숫자만큼 생성됨을 확인할 수 있다.
3. Spark 간단한 예제 실습
간단한 실습을 하기 위해 먼저 master 서버에 작업을 올린다.
콘솔 창을 오픈 하고 아래와 같이 spark-shell을 실행해준다.
spark-shell --master spark://<사용자_hostname>:7077
정상적으로 오픈이 되었다면 "welcome to spark" 문구가 보이게 된다.
또한, 스파크 웹 콘솔 화면에서도 Running Application List에 Spark shell이 올라오게 된다.
아래와 같은 텍스트 파일에서 lines.count() 출력하는 간단한 실습이다.
테스트 방법은 간단하다. 텍스트 파일을 불러와서 라인수를 조회하는 명령어를 수행하면 된다.
scala> var lines = sc.textFile("/Users/user/Documents/words.txt")
lines: org.apache.spark.rdd.RDD[String] = /Users/user/Documents/words.txt MapPartitionsRDD[1] at textFile at <console>:23
scala> lines.count()
res0: Long = 4
'분산처리 > Spark' 카테고리의 다른 글
| Spark History Server 오류 (0) | 2022.07.31 |
|---|---|
| 스파크란? -기본 (0) | 2022.07.29 |